INTRODUCTION
BACKGROUND
We know that in the construction site area, construction workers must wear helmets to guard against falling objects. But even though supervisors give this requirement to construction workers, someone always forgets or chooses not to wear a helmet for various reasons, which brings great safety risks to his life. Previously, supervisors often patrolled regularly to detect whether each person was wearing a helmet correctly, but this was time-consuming and labor-intensive, and the supervisors were unable to monitor in real time. Therefore, they want to be able to use visual computing to determine whether construction workers are wearing helmets, and if someone is found not wearing a helmet, a warning will be issued.
MOTIVATION
Object recognition or action recognition based on visual computing has received a lot of attention and made great progress, such as ImageNet, YOLO, and so on. However, this area is still full of many challenges, such as how to improve the speed of video transmission, the speed of model recognition, and the generalization ability of models. This work will focus on these problems and implement a vision gateway based on YOLOv5s Model.
METHOD
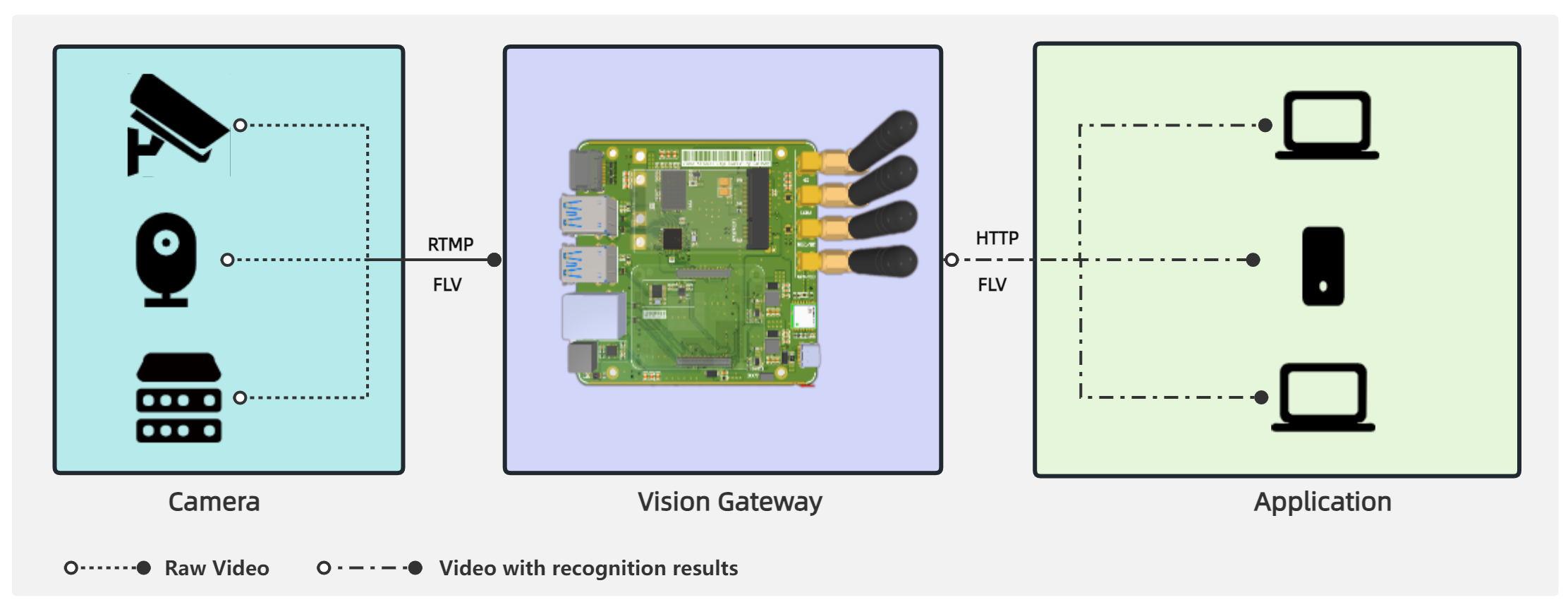
1. Mlti-camera video concurrent pull stream
This work uses the Hikvision camera that supports RTSP protocol, according to the product manual can be known to pull the video stream as shown in the base code 1. To realize multiple pulling cameras, we use a multi-threaded approach.
import cv2
# Camera Login Information
ip='192.168.2.111'
user='admin'
password='123456'
# rtsp://[username]:[passwd]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream
capture = cv2.VideoCapture("rtsp://"+ user +":"+ password +"@" + ip + ":554/h264/ch1/main/av_stream")
ret, frame = capture.read()
cv2.namedWindow(ip, 0)
cv2.resizeWindow(ip, 500, 300)
while ret:
ret, frame = capture.read()
cv2.imshow(ip,frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
capture.release()
Code 1. Camera Video Stream Pulling Based on RTSP Protocol.
2. Detect people's body and avatar in video streams
We used some of the detectors that come with in to detect human bodies, and avatars in video frames (pictures). These detectors have been successfully applied to pedestrian detection in still images. They can be directly passed as parameters to the program HaarFaceDetect.
- Upper body detector (most fun, useful in many scenarios!)
- Lower body detector
- Full body detector
import cv2
cv2.namedWindow("Helmet")
# download from opencv
# haarcascade_fullbody.xml for body
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
while True:
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
# detect avatar
faces = face_cascadedetectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(20, 20), flags=cv2.CASCADE_SCALE_IMAGE)
# lable avatar
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('Helmet', frame)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
Code 2. Getting the human body, and avatar region in a video stream.
3. Helmet Recognition Model based on YOLOv5
A. Dataset [Safety-Helmet-Wearing-Dataset]SHWD provide the dataset used for both safety helmet wearing and human head detection. It includes 7581 images with 9044 human safety helmet wearing objects(positive) and 111514 normal head objects(not wearing or negative). The positive objects got from goolge or baidu, and we manually labeld with LabelImg. Some of negative objects got from SCUT-HEAD. We fixed some bugs for original SCUT-HEAD and make the data can be directly loaded as normal Pascal VOC format. Also we provide some pretrained models with MXNet GluonCV.
path: ../datasets/helmet # dataset root dir
train: images/train # train images
val: images/val # val images
# Classes (3 classes)
names:
0: person
1: head
2: helmet
Code 3. Configurate Dataset.
B. Create Labels We use JingLingBiaoZhu tool to lable our images
After using an annotation tool to label our images, export our labels to YOLO format, with one *.txt file per image (if no objects in image, no *.txt file is required). The *.txt file specifications are:
- One row per object
- Each row is class x_center y_center width height format.
- Box coordinates must be in normalized xywh format (from 0 - 1). If your boxes are in pixels, divide x_center and width by image width, and y_center and height by image height.
- Class numbers are zero-indexed (start from 0).
import numpy as np
def convert(size, box):
"""
convert labled [x1,y1,x2,y2] to location using by YOLOv5
:param size: [w,h]
:param box: [x1,y1,x2,y2]
:return: [x,y,w,h]
"""
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
dw = np.float32(1. / int(size[0]))
dh = np.float32(1. / int(size[1]))
w = x2 - x1
h = y2 - y1
x = x1 + (w / 2)
y = y1 + (h / 2)
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return [x, y, w, h]
Code 4. Convert the image to the format that YOLOv5 needs.
C. Organize DirectoriesOrganize your train and val images and labels according to the example below. YOLOv5 assumes /coco128 is inside a /datasets directory next to the /yolov5 directory. YOLOv5 locates labels automatically for each image by replacing the last instance of /images/ in each image path with /labels/.
../datasets/helmet/images/im0.jpg # image
../datasets/helmet/labels/im0.txt # label
Code 5. Organize Directories.
D. Select a ModelSelect a pretrained model to start training from. Here we select YOLOv5s, the second-smallest and fastest model available.
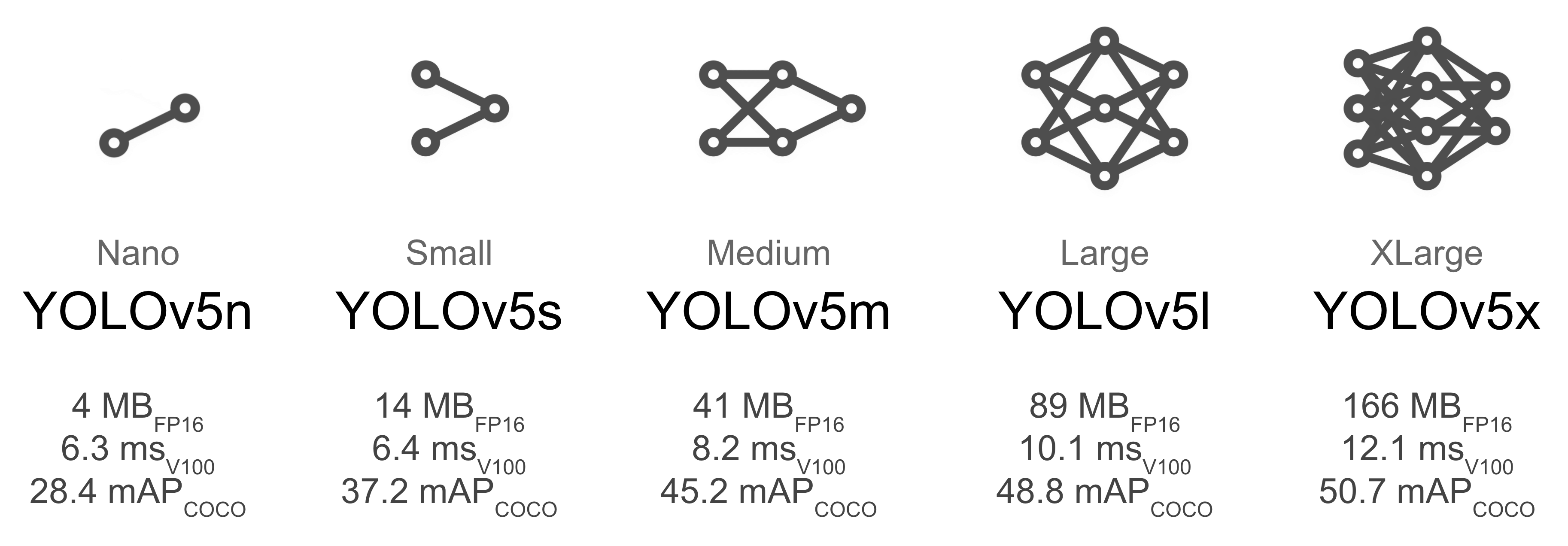
Figure 2. YOLOv5 models.
E. TrainTrain a YOLOv5s model on helmet by specifying dataset, batch-size, image size and either pretrained --weights yolov5s.pt (recommended), or randomly initialized --weights '' --cfg yolov5s.yaml (not recommended). Pretrained weights are auto-downloaded from the latest YOLOv5 release.
All training results are saved to runs/train/ with incrementing run directories, i.e. runs/train/exp2, runs/train/exp3 etc. For more details see the Training section of our tutorial notebook.
python train.py --img 640 --epochs 3 --data helmet.yaml --weights yolov5s.pt
Code 6. Start train model.
RESULT
KEYWORDS
Edge Computing, YOLOv5, CV2, Body Recognition, Face Recognition.
MATERIALS
About YOLOv5
Figure 3. YOLOv5 models.
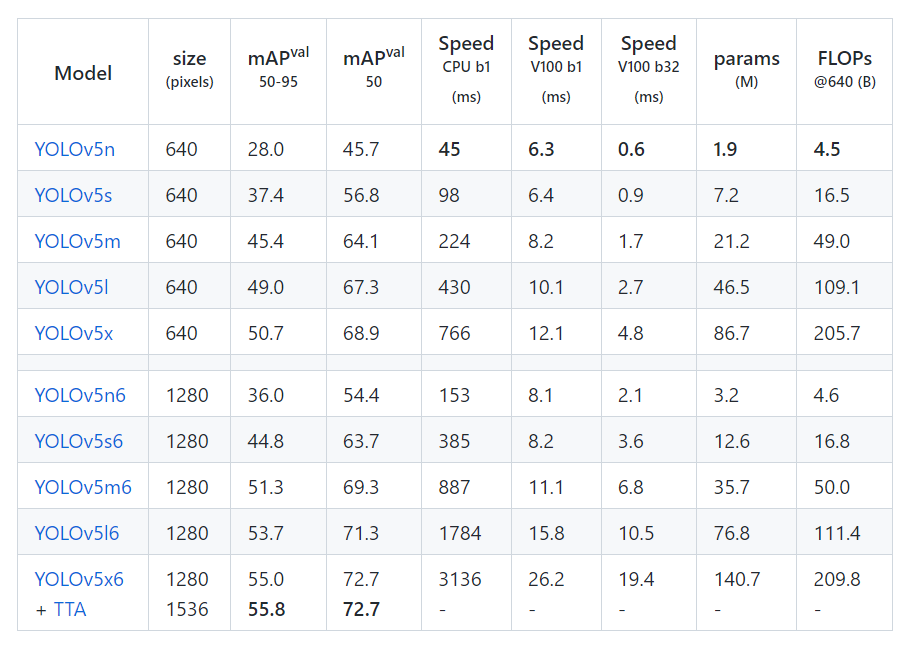
Figure 4. Comparison of parameters of different models.
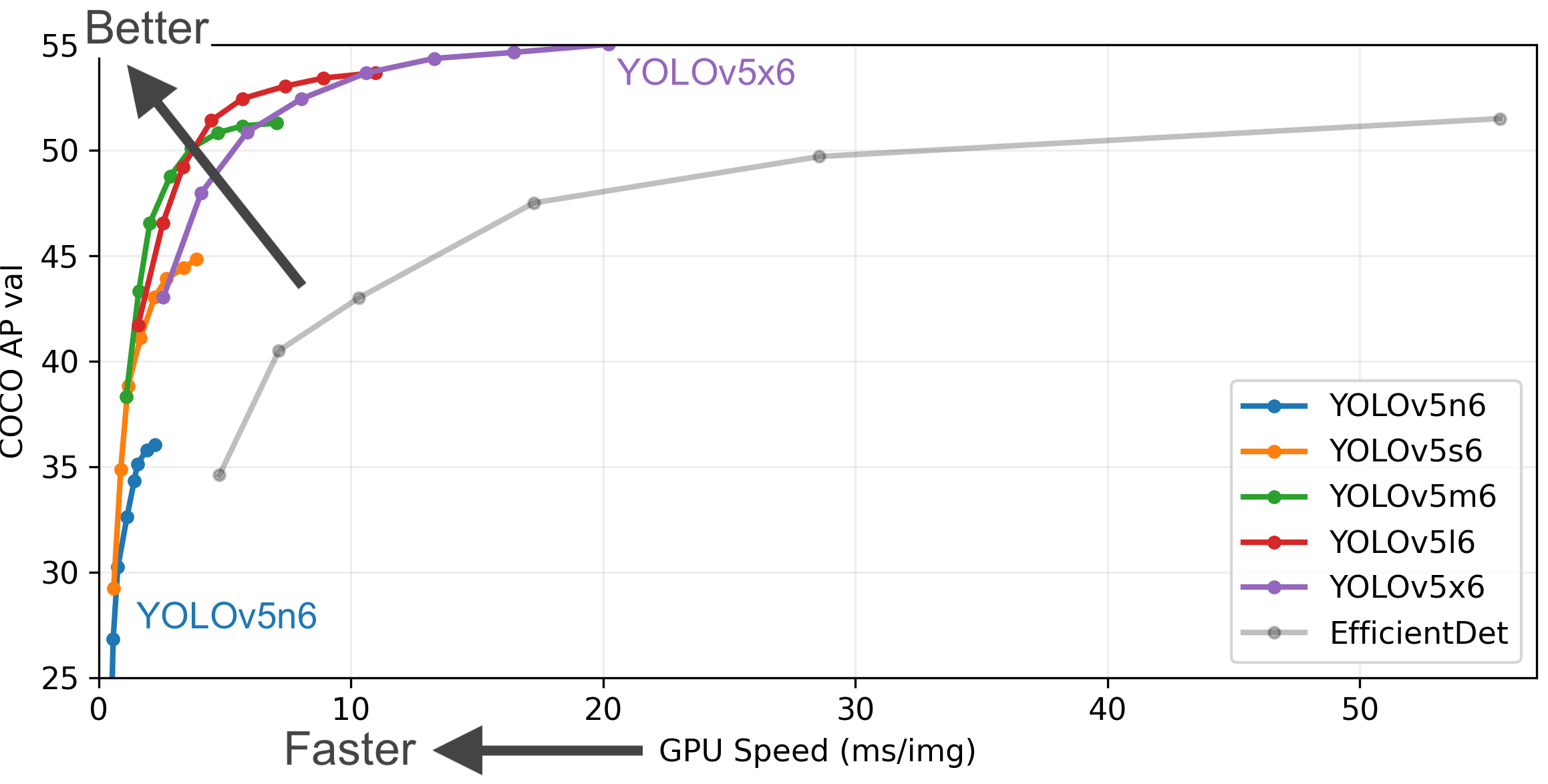
Figure 5. Training and effects of different models in YOLOv5.
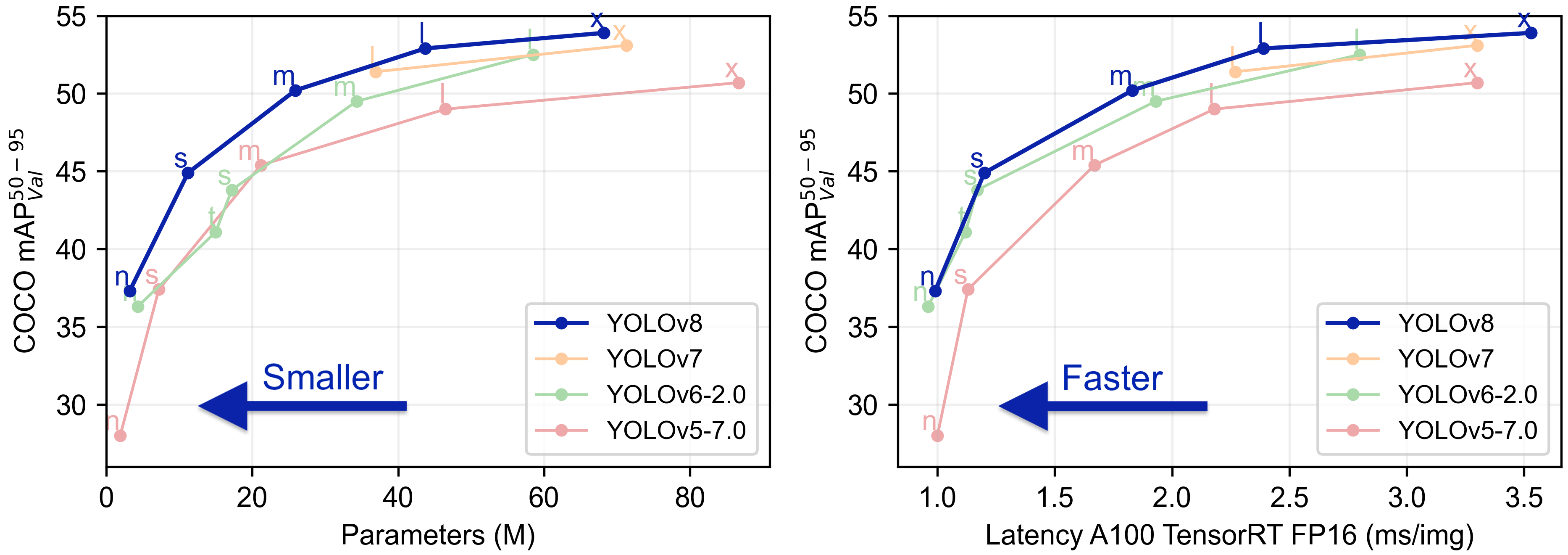
Figure 6. Comparison with others version.

Figure 7. Training result on COCO128 dataset.
HARDWARE
Video 1. Someone famous in Source Title.
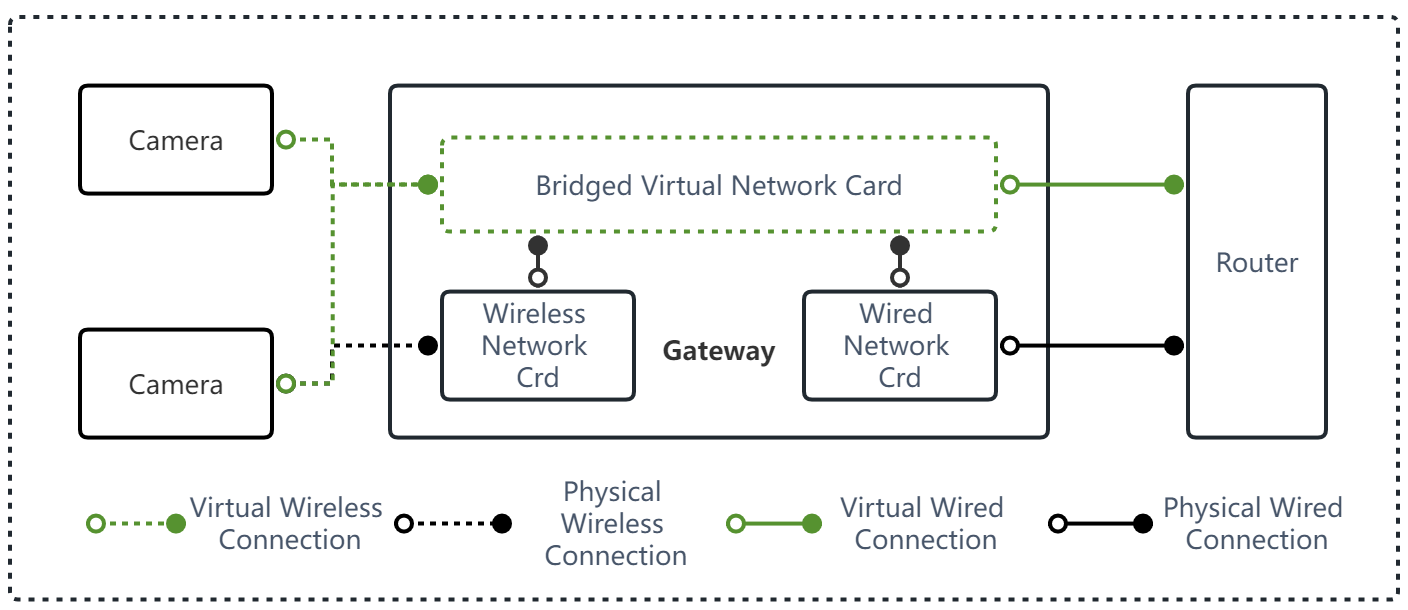
Figure 8. Bridging a Wireless NIC to a Wired NIC.
We designed a visual gateway based on the Raspberry Pi Computing Module 4 and set the wireless network card to AP mode for connecting the attached camera and connecting to the Internet by bridging with a wired connection.
To increase the inference speed of the machine learning model, we added a Google TPU gas pedal with 4TOPS of arithmetic power.
At the same time, we added some basic sensors, such as temperature and humidity, motion sensors, GPS, etc. to detect the environment around the gateway, as well as LoRa and 4G capabilities.
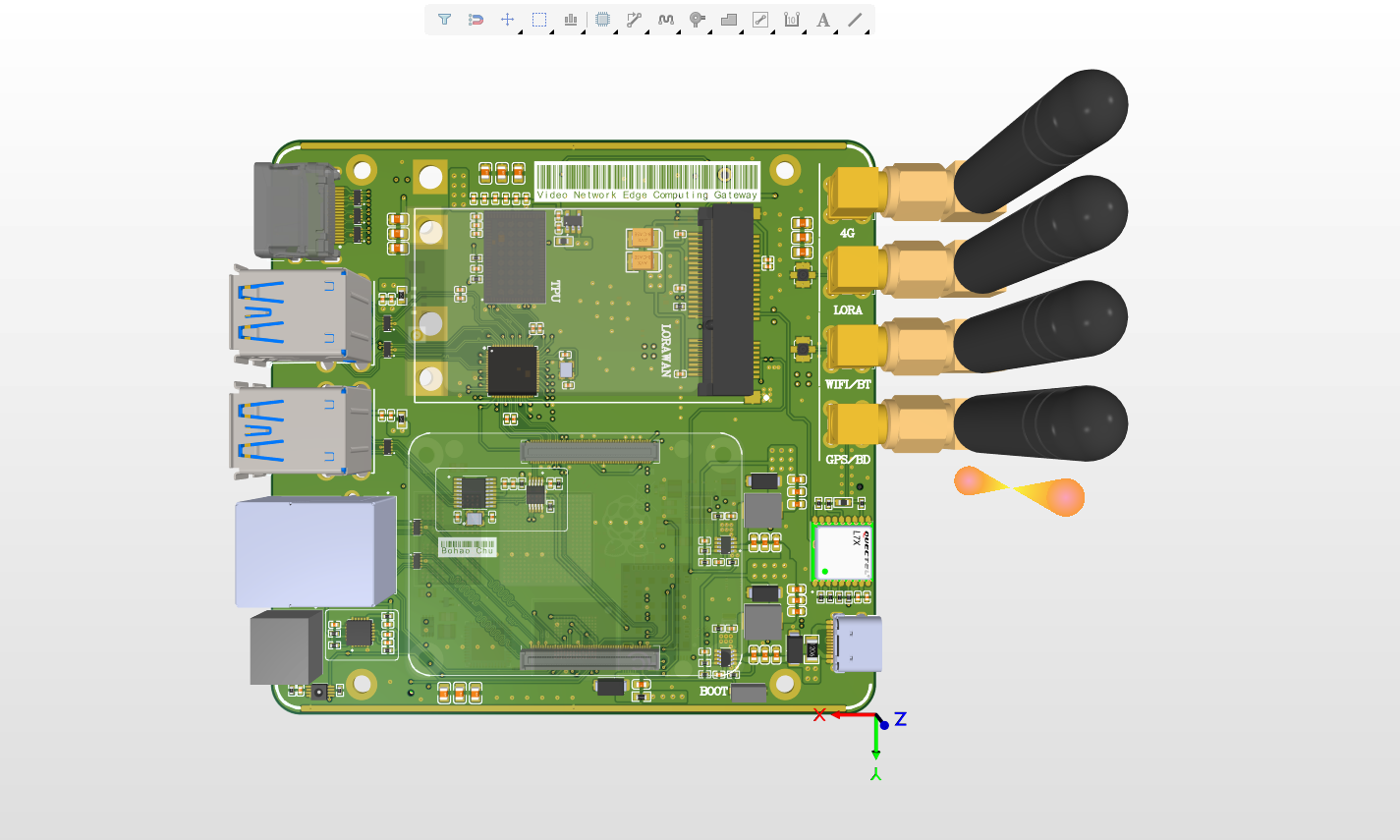
Figure 9. 3D model of our gateway.

Figure 10. Gateway after soldering.
TRAINNING
We used the open source Data Safety-Helmet-Wearing-Dataset. Many thanks to the authors as well as the photo participants. Currently, we just use the training data to train the model briefly, and the effect is as described by the authors all the time, the next step, we will port the model to the web for real-time video recognition.










Figure 11. Model evaluation results.
HARDWARE
TO DO ...